


A retrieval-focused agent (Agentic RAG) is an AI system where a large language model (LLM) agent uses tools to find, evaluate, and act with external evidence. Unlike a static retrieval augmented generation (RAG) pipeline, which uses retrieval for context delivery, a retrieval agent treats retrieval as a set of tools used via reasoning. Instead, it has to decide which retrieval tool to call, how to query it, whether the returned material is sufficient, and whether another retrieval step is required.
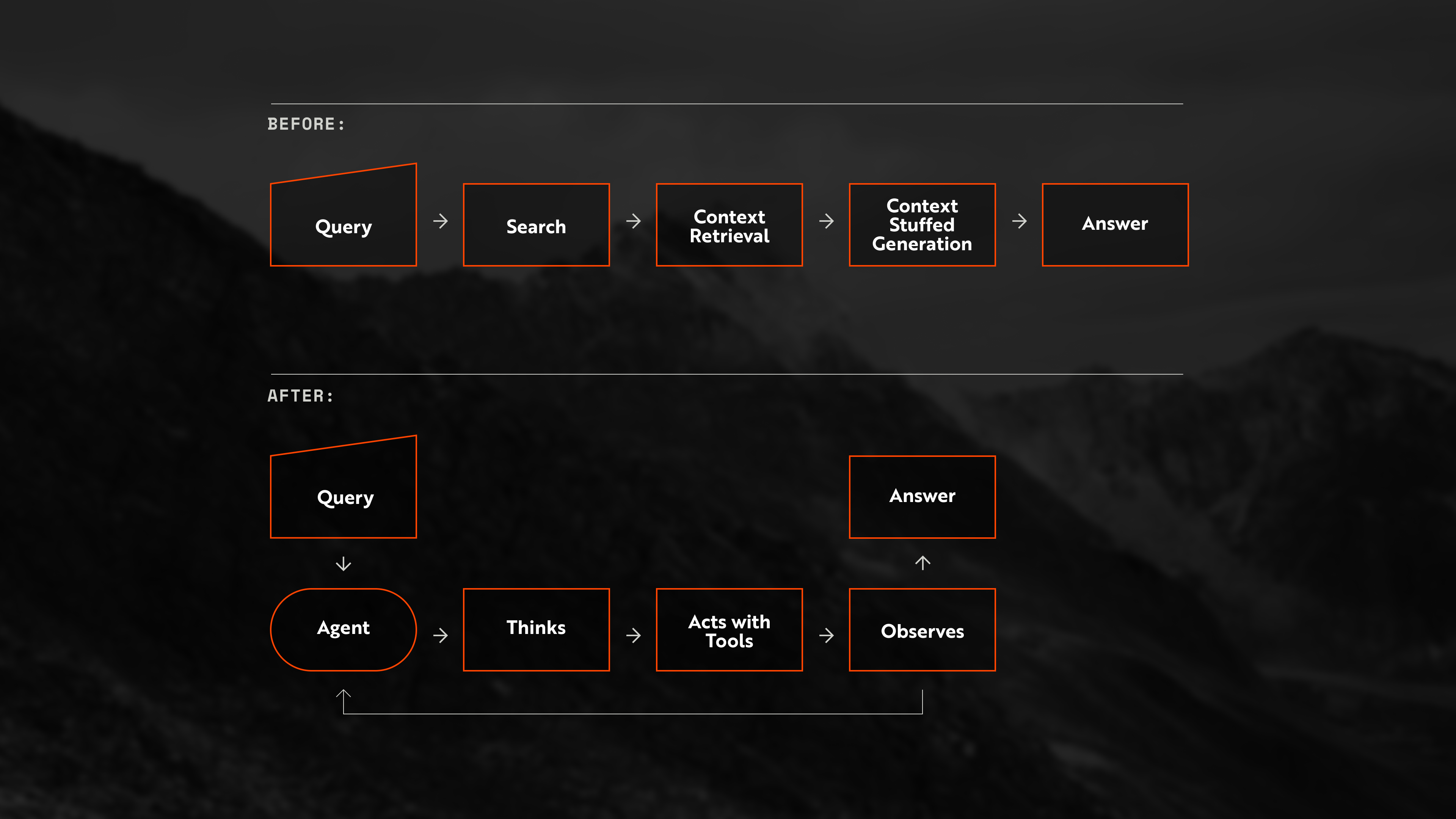
After: Agentic RAG uses search and document exploration tools, iterating until it has enough evidence to answer.
Three Variables Determine Retrieval-Focused Agent Performance
A retrieval agent fails for different reasons depending on whether the bottleneck sits in the model, the tools, or the prompts.
Retrieval-focused agent performance is a function of three independent variables: the reasoning capability of the model, the coverage and quality of the tools available to it, and the behavioral guidance encoded in the prompts. Each variable can become the binding constraint. A capable model with weak tools fails, but a strong tool suite paired with poor guidance also fails.
The model is the reasoning engine. In an agent, the model also plans, selects, evaluates, and iterates. A more capable model handles multi-step retrieval chains with greater reliability, judges whether retrieved context actually resolves the query, follows tool-use procedures with higher fidelity, and recovers more cleanly when a retrieval attempt returns noise. Model selection carries more weight in agent architectures because the model is doing more work.
The tools in this case are the retrieval stack. Tools are the mechanisms by which the agent reaches data: keyword search, vector search, SQL, APIs, document fetchers, and structured retrievers. Tool performance depends on coverage, precision, efficiency, and reliability. A capable model can compensate for some tool limitations through query reformulation and retry, but a retrieval surface that cannot reach the right data creates a hard ceiling on performance.
The prompts are the operating procedures. Prompts in agentic systems are behavioral specifications. They tell the agent when to invoke which tool, how to formulate queries for each tool type, how to evaluate retrieved context, when another retrieval step is required, how to handle ambiguity and failure, and what the final output should look like. If knowledge is distributed across multiple systems, prompts also guide the agent toward the right documents, sources, and systems in the right order.
A Good Retrieval Stack Combines Document Understanding and Search
A retrieval agent needs more than access to data, it needs a retrieval surface that preserves structure, meaning, and usability.
A good retrieval stack for agents combines several capabilities into a surface the agent can query directly, including document understanding, lexical and semantic retrieval and reranking. Some corpora also benefit from image understanding, table extraction, OCR recovery, structured field extraction, or modality-specific parsers. These are not the only useful components, but a short sample of the things that go into a strong retrieval system.
Just as important, those capabilities have to be composable. Multi-step reasoning often requires the agent to move across retrieval methods and modalities rather than rely on a single pass through one tool. A useful retrieval stack might let the agent combine lexical retrieval with semantic retrieval, render document structure in an LLM understandable format, and connect text evidence with tables, images, or other extracted artifacts when the corpus requires it.
Those capabilities have to be composed into a retrieval surface the agent can use step by step. The agent should be able to query the corpus, inspect ranked results, refine its search, and act on grounded evidence without losing provenance or structural metadata along the way. When those components are able to be composed cleanly, the agent can excel at retrieving and understanding documents to their fullest.
Domain Benchmarks Reveal Whether Retrieval Agents Actually Work
A system that scores well on easy benchmarks or common benchmark datasets can still fail or be subpar the moment the domain gets specific.
LLM and agent capabilities are often evaluated by using benchmark datasets that consist of questions and conversations to run agents over and expected gold answers to measure agent outputs against. They can be thought of as exams for agents. They are used to test agents on different complexities of questions and within different domains. For agentic RAG, benchmarks are useful because they measure the interaction between retrieval and reasoning, not just one or the other in isolation. They expose whether the agent can find important documents and passages, recover relationships across sources, and act on evidence that is distributed rather than neatly localized. There are many academic benchmark datasets that contain complex retrieval tasks that LLMs are often evaluated against, like BrowseComp, HotpotQA, and more. However, they often produce scores that are meant to understand agent performance at the extremes instead of performance for the specific task an organization will use an agent for. Understanding agent performance for a specific use case is the most important benchmark for an organization implementing agentic systems in daily work. In order to do so, the data and problems the agent is evaluated against must be in domain and reflect close to real usage. Doing so will also allow for organizations to tune agent performance for their domain and problem set, and potentially minimize cost by choosing the most cost-effective yet performant models for their use case.
At Legion Intelligence, our Army Doctrine dataset is a useful example of that kind of benchmark. Army Doctrine makes complex retrieval failure modes visible because it is a structured system of knowledge, not a flat corpus. Publications exist in relation to each other, concepts are defined across documents, and meaning is often distributed across that graph rather than stored in a single paragraph. Meaning is also distributed within long documents across sections. Hierarchy and document structure also impart value, so chapters, functions, principles, tasks, and sub-tasks cannot be flattened without loss. Terminology is precise and sometimes overloaded. Answers also have to remain grounded under uncertainty, ambiguity, and incomplete information. That combination makes doctrine a useful benchmark because it tests whether the system can retrieve the right material, preserve its structure, and connect it correctly.
Legion’s Army Doctrine benchmark data is built around questions that are difficult in the specific way retrieval-focused agents often fail: they cannot be answered by lifting one sentence from one document. Each example is a query over a collection of doctrine documents. Each query is paired with an expected answer, the source documents that must be read and the specific supporting context passages from those documents. In practice, this dataset tests whether the agent can retrieve across doctrinal publications, preserve the distinctions between them, and synthesize them into a grounded answer. Because this dataset is extremely rich, it becomes possible to see failure patterns for an agent and whether they originate from document retrieval, passage selection, or final grounded synthesis.
For example, one benchmark question asks, "Which stability mechanism best aligns with the purpose of the command and control warfighting function, and what doctrinal connection supports this assessment?" In order to answer this question correctly, the agent must move between documents ADP 3-0 and ADP 6-0: one document provides the stability mechanisms, while the other defines the purpose of command and control. The correct answer is not a direct quote from either text in isolation. It emerges from aligning concepts across publications and showing the doctrinal connection that supports the conclusion.
Benchmarking on in-domain problems matters. The point of the benchmark is to not only understand if the system works for challenging problems, but also to validate that Legion’s agentic system serves the use cases that matter most to our customers.
For a framework on building the evaluation infrastructure to run these benchmarks at scale, see Building an Evaluation Platform That Scales.
Legion Intelligence Benchmarked on Army Doctrine
This benchmark tests multi-document doctrinal synthesis, then shows how Legion’s default retrieval agent improves further through evaluation-driven domain tuning.
Benchmark Metrics
Given all of the questions and associated reference answers, annotated documents and passages from the Army Doctrine, this benchmark takes the questions, runs them through the agent and compares them with the answer and evidence the agent produces. Those answers translate into two metrics: did the system give a good answer (answer quality), and did it find the right information to support that answer (retrieval quality).
For answer quality, we use another LLM to grade each response on a 1–5 (Likert) scale by comparing it to a reference answer. In practice, this score is most useful in two ways. First, it lets us compare different versions of the system to see which one performs better. Second, it gives a practical bar for success: once answers reach around a 3 or 4 out of 5 on the Legion scale, they generally match what a human would consider a solid, acceptable response. This matters because many of these questions are not about copying exact wording. They require reasoning across multiple sources, so a good answer might look different from the reference while still being correct and well-supported.
For retrieval quality, we measure how closely the system’s supporting passages match a set of known “correct” passages. This is measured as the overlap (ROUGE-L) between the system's passages and the known correct passages, normalized to a score between 0 and 1. This metric is intentionally strict. Sometimes the system finds useful information that wasn’t in the original reference set, which means the score can slightly understate how well it actually performed.
Legion’s Agents Measured and Improved
To start, a generalized retrieval agent shipped with the Legion platform was run over this benchmark data. This was not a doctrine-specific system tuned for the benchmark. This reflects out-of-the-box performance from one of Legion's generalized default retrieval agents. The Legion retrieval stack starts at ingestion. Legion's document pipeline parses PDFs, preserves layout, extracts concepts, entities, semantic relationships and document structure before the material is written into the document store. This is important because headings, section boundaries, hierarchical relationships, and layout cues often carry meaning, especially in long doctrinal publications where the difference between a chapter heading, a numbered task, and an explanatory paragraph affects how the material should be retrieved and interpreted. The agent works with a search surface on top of that document store represented by tools. This lets the agent find relevant documents and passages and move through sections and subsections the way a human analyst reads doctrine. The agent itself is instructed on how to use these tools, but it is not handed a fixed retrieval path. The model decides how to explore, which searches to issue, when to traverse a document, and when it has enough evidence to answer.
On the Army Doctrine benchmark, a set of 259 challenging questions that require pulling information from multiple documents, the out-of-the-box system performed well. It achieved an average answer quality score of 3.74 out of 5, meaning most responses approach human performance. Its retrieval quality score was 0.69 out of 1, showing that the passages it found strongly overlapped with the expected sources.
While the baseline system performs well out of the box, we introduced a light round of domain-aware tuning to see how easily users could push performance further in practice. The retrieval stack and tools remained unchanged. Instead, the updates focused on how the agent reasons through doctrine. The prompt was modified to explicitly decompose questions, explore more linkages between documents, and compare candidate concepts rather than selecting the first plausible match.
With those changes in place, performance improved further. The average answer score increased from 3.74 to 3.87 out of 5, and the retrieval score rose from 0.69 to 0.77. These gains reflect a more consistent ability to both find the right material and use it in the final answer. In practice, the agent is retrieving passages that better match the expected evidence and incorporating them more directly into its reasoning, rather than stopping at partially relevant context or loosely supported conclusions.
This is the key insight from this experiment: retrieval-focused agent performance is not just about having a strong model or a capable retrieval stack. It is about how effectively the agent uses those components to find and apply the right evidence. Even when the underlying system is already strong, small changes to how the agent is guided can produce meaningful gains around retrieval, data exploration and answer completeness.
Performance is constrained independently by the model, the retrieval surface, and the prompts. If any one of these is under-optimized, it becomes the bottleneck. Evaluation provides a practical way to identify that constraint and improve it. In this benchmark, the constraint was not access to information, but how the agent searched for it and incorporated it into its reasoning. Addressing that gap led to measurable improvements without changing the underlying system.
.png)